The Road To Serverless: Intro & Why
Author: Ed Huang (i@huangdx.net), CTO@PingCAP
The reason for this was a conversation with a friend about an interesting topic:
“If I were to provide free database cloud services for 100 million users, how should the system be designed?”
To answer this question, in my previous two blog posts, I vaguely mentioned that we are using some new perspectives and ideas to approach and build database services. We have turned these thoughts into actual products: tidb.cloud/serverless. Many friends are interested in learning more details about TiDB Cloud Serverless (hereinafter referred to as TiDB Serverless), as the whole article might be very long, I will divide the entire series into 3 parts. This is the first part and I will introduce some background information and why we need to do Serverless.
Some friends may not be familiar with TiDB, so allow me to give a quick introduction to TiDB first. For those who are already familiar with TiDB, you can skip this section. Here are some key terms and definitions:
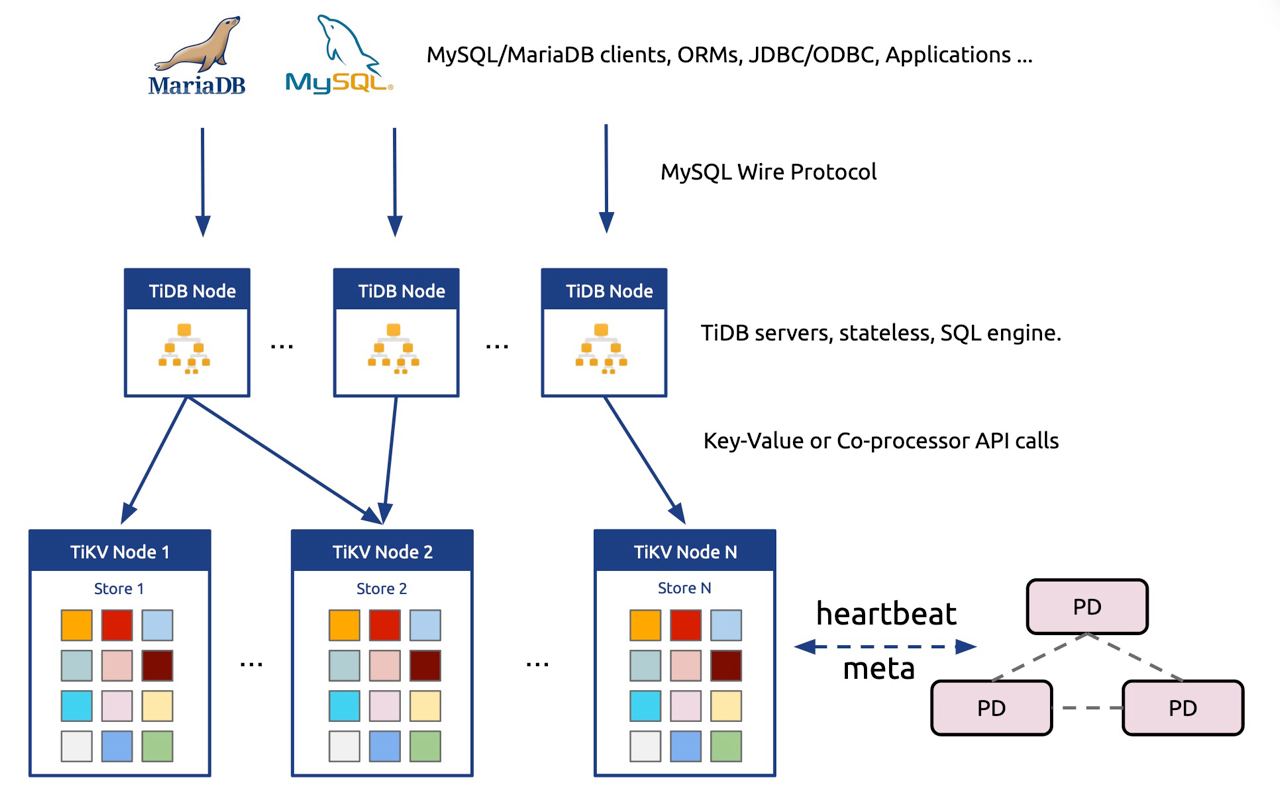
- TiDB: Specifically refers to a distributed SQL database composed of components: tidb-server (responsible for SQL parsing and execution), tikv-server (responsible for data storage), and pd-server (responsible for metadata and scheduling).
- TiDB Cloud: A cloud service that provides fully managed TiDB on the cloud.
- TiDB Cloud Serverless: A cloud service that provides TiDB with cloud-native storage and multi-tenant features. It offers extremely low usage costs and startup times, adopts a Pay-As-You-Go payment model, and is completely free for developers in small-scale scenarios.
In early 2015, we embarked on an ambitious plan inspired by Google Spanner and F1 (I prefer to call it inspiration). We aimed to build an ideal distributed database: supporting full-featured SQL, using MySQL protocol and syntax, embracing ACID transaction semantics without compromising consistency; providing transparent and limitless horizontal scalability to dynamically adjust the physical distribution of data based on traffic and storage characteristics to achieve maximum hardware utilization; ensuring high availability and self-healing capabilities to reduce the burden of manual operations and maintenance (sounds too good to be true, right? 😊).
Driven by these goals, we made the following technical decisions from the very beginning:
- Highly modular architecture: tidb-server handles connection handling, SQL parsing, optimization and execution, tikv/tiflash handle storage (and a little bit distributed execution), and pd-server handles metadata storage and initiates scheduling commands.
- The storage layer adopts a Share-Nothing architecture with a Key-Value form (tikv) that supports ACID transactions to support elastic scalability, while other modules are designed to be stateless as much as possible. For instance, once the basic TiDB cluster bootstrap is completed, many pieces of information can be stored in TiDB’s own system tables, such as the statistics used for SQL optimization. The aim is to minimize localized state (e.g., avoiding separate local and global indexes) to reduce the complexity of fault recovery logic.
It is evident that this design aims for strong scalability and large-scale scenarios. In the early days, TiDB’s idea originated from replacing sharding and partitioning solutions for massively scaled MySQL deployments. This strategy has been highly successful, validated by numerous customers, and has even replaced some well-known NoSQL systems known for their scalability. For example, Pinterest mentioned in their blog post that they successfully replaced their HBase with TiDB.
Looking back at the decisions made back then, we think TiDB is on the right track:
Clear separation at the module level, with compute, storage, scheduling, and metadata management handled by different services. This design choice keeps complexity contained within the modules and facilitates easy horizontal scalability and load balancing of stateless components like TiDB’s SQL layer.
Although TiDB appears to be a relational database to users, its storage layer utilizes a simple key-value abstraction, extremely fine-grained scheduling units called Regions (or Range, containing 96MB of continuous key-value pairs), and flexible data movement primitives. The benefit is the ability to move data at a very granular level, allowing the business layer to theoretically place data in any way desired. This formed the foundation for subsequent features like Placement Rules.
However, over time, we gradually identified two trends:
- Once OLTP workloads can be effectively supported by horizontal scalability, it is a natural choice for a SQL database to handle simple real-time OLAP queries on top of it. This observation gave rise to TiFlash.
- Not all businesses initially have such a massive amount of data that requires distributed storage. However, growth expectations are real. Therefore, the more important question is whether the development experience can remain consistent when the data and workload grow to the point where distributed database capacity is needed (e.g., sharding and partitioning can disrupt the development experience). At the same time, there should be a low-cost starting point when the data volume is initially small.
The above requirements present several limitations in traditional Shared-Nothing architecture:
For the first trend, the integration of OLTP and OLAP comes with high costs in a traditional Shared-Nothing architecture. The reason is that, for OLAP applications, CPU often becomes the bottleneck. To achieve good performance on OLAP, we can only add more computing resources (i.e., physical servers). However, OLAP workloads are typically not online services, so these workloads do not necessarily require 24⁄7 exclusive access to these resources. Nevertheless, we have to prepare these resources in advance to run these workloads. Even though TiFlash provides excellent elasticity and scalability at the storage layer (we can create TiFlash replicas for specific tables on-demand), it is challenging to achieve elastic scalability for computing resources in a non-cloud environment. For the second trend, traditional Shared-Nothing architecture in distributed databases usually assumes that all physical nodes have equal hardware configurations; otherwise, it would increase the difficulty of scheduling. Moreover, in pursuit of ultimate performance, multi-tenancy design is often sacrificed because most database deployments in the cloud are exclusive to applications. To reduce database usage costs, there are two common approaches:
- Multiple tenants share a database cluster.
- Separate hot and cold data, using cheaper hardware to store cold data.
Additionally, the migration of businesses to the cloud is another commonly mentioned trend, which I won’t delve into as it has been extensively discussed. Based on the assumptions above, let’s consider a question: If we were to rewrite TiDB today, what new assumptions should we make and what choices should we make? The goal is to cover more use cases and achieve higher stability.
New assumptions:
- Everyone loves a low-cost start.
- On-demand pricing with support for Scale-to-Zero is desirable. It’s a great experience to not be charged when not in use, and when there are a massive number of users, the majority of them are inactive, following the Pareto principle.
- For the relational database market, OLTP remains mainstream, while the most important aspects for OLAP are elasticity and low cost (rather than just performance). Another often overlooked scenario is lightweight data transformation, as seen in tools like dbt, but frequent data movement between different data service providers is not a good user experience. If data transformation (ETL and Reverse ETL) and serving can be completed in the same database, it will greatly simplify the complexity of data architecture.
- There is a large amount of cold data and a small amount of hot data, but it’s often difficult to clearly define the boundary between them (similar to not being able to prevent me from replying to a thread on my social media feed from three years ago).
- There are online service scenarios with large data volumes (e.g., social networks), but they always come with highly selective secondary indexes (e.g., user_id/account_id). Under the coverage of these indexes, the amount of data scanned in a query is not significant. In such scenarios, the cache hit rate is crucial.
- CPU is challenging to scale, while storage is easily scalable. CPU is expensive, while storage is cost-effective.
- Cloud infrastructure will be prevalent both in the cloud and on-premises (object storage, container platforms, etc.).
- Stable and predictable performance is better than unstable high performance.
Our choices in TiDB Serverless:
- Built-in multi-tenancy that supports a vast number of fine-grained (small) tenants at a low cost. After all, unit costs can only be continuously reduced by resource sharing.
- Leveraging different storage and compute services instead of equivalent physical machines, especially making good use of object storage.
- Maintaining the separation design but delivering it as a platform service composed of a set of microservices, rather than as a single software package.
The next two articles will provide a detailed introduction to the cloud storage engine and multi-tenancy design of TiDB Serverless.